The IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU) 2019 ended last week, and here is a list (with very brief summaries) of some papers I found interesting and/or relevant to my research.
Speech recognition: new directions
Hybrid DNN-HMM systems
-
From senones to chenones: tied context-dependent graphemes for hybrid speech recognition
- Conventional knowledge: phonemes perform better than graphemes for hybrid models.
- This paper from Facebook AI shows that tied context-dependent graphemes (chenones) can perform better than senones on Librispeech (3.2% WER compared to 3.8% in Kaldi TDNN-F models).
- Chenones can better exploit the increase in model capacity and training data compared to senones.
- Graphemic systems recognize proper nouns and rare words with higher accuracy.
- Why do graphemic systems not perform as well in Kaldi? Dan Povey seems to think this is because Kaldi TDNN models are smaller. Duc Le (the first author on the paper) hypothesized that this is because Kaldi chain models use full biphones instead of triphones.
-
Incremental lattice determinization for WFST decoders
- The lattice determinization in WFST decoders (in Kaldi, for instance) happens at the utterance level. In this paper, an algorithm is proposed to perform this incrementally, i.e., in an online fashion.
- Essentially, the lattice is broken into chunks with special symbols joining the chunks, and each of these chunks is determinized independently.
- There are several design decisions such as chunk size, determinize delay, etc.
- The code is available in Kaldi here.
End-to-end models
-
MIMO-SPEECH: End-to-end multi-channel multi-speaker speech recognition
- Best paper award at ASRU2019.
- This paper proposes a fully end-to-end neural framework for multi-channel multi-speaker ASR comprising of: (i) a monoaural masking network, (ii) a multi-source neural beamformer, and (iii) a multi-output speech recognition model.
- A masking network predicts masks for the different speakers, which is then applied to the beamformed input to get features for different speakers.
- A shared encoder-decoder system then performs speech recognition, with an added CTC loss. Permutation-invariant training is also used since there are several speakers.
- Training data scheduling plays an important role in improving performance, since it is difficult to train such a system.
-
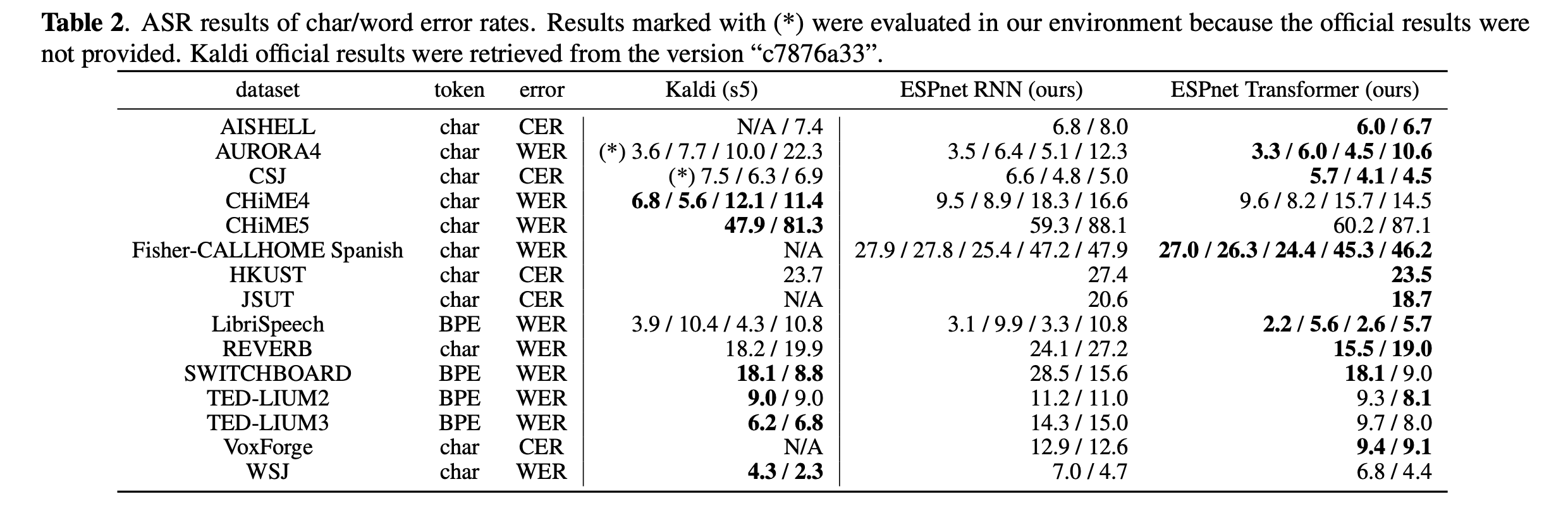
A comparative study on transformer vs RNNs in speech applications
- An extensive comparison of transformers and RNNs is performed for 15 ASR, 1 speech translation, and 2 TTS tasks.
- This table summarizes the results of ASR experiments. Transformers are better than RNNs in 13/15 ASR experiments. ESPNet was used to perform experiments on RNNs and transformers.
Other
-
Integrating source-channel and attention-based sequence-to-sequence models for speech recognition
- Best student paper award at ASRU 2019 (also my personal favorite).
- ASR comprises primarily two kinds of models: noisy source-channel (SC) models such as DNN-HMM and CTC for acoustic modeling and a separate LM with lexicon-based decoding, and attention-based seq2seq models which perform everything in a single model.
- This paper proposes a framework called Integrated Source-Channel and Attention (ISCA) which combines the advantages of both models. Note that a special case of the framework is this paper which uses CTC loss as a multi-task objective to enforce monotonic alignment in attention-based models.
- The framework is primarily an extended SC model, in that the posteriors from a SC model are first obtained and then the attention-based decoding is performed conditioned on these posteriors. ISCA performs frame-synchronous decoding using the SC-based model first and then rescores hypotheses with the attention-based model.
- This means that both the models can work with subword units of different levels.
- An obvious improvement in the current work is to extend it to sequence-level objectives in the SC, and Quijia Li (the first author) said they are working on this now.
-
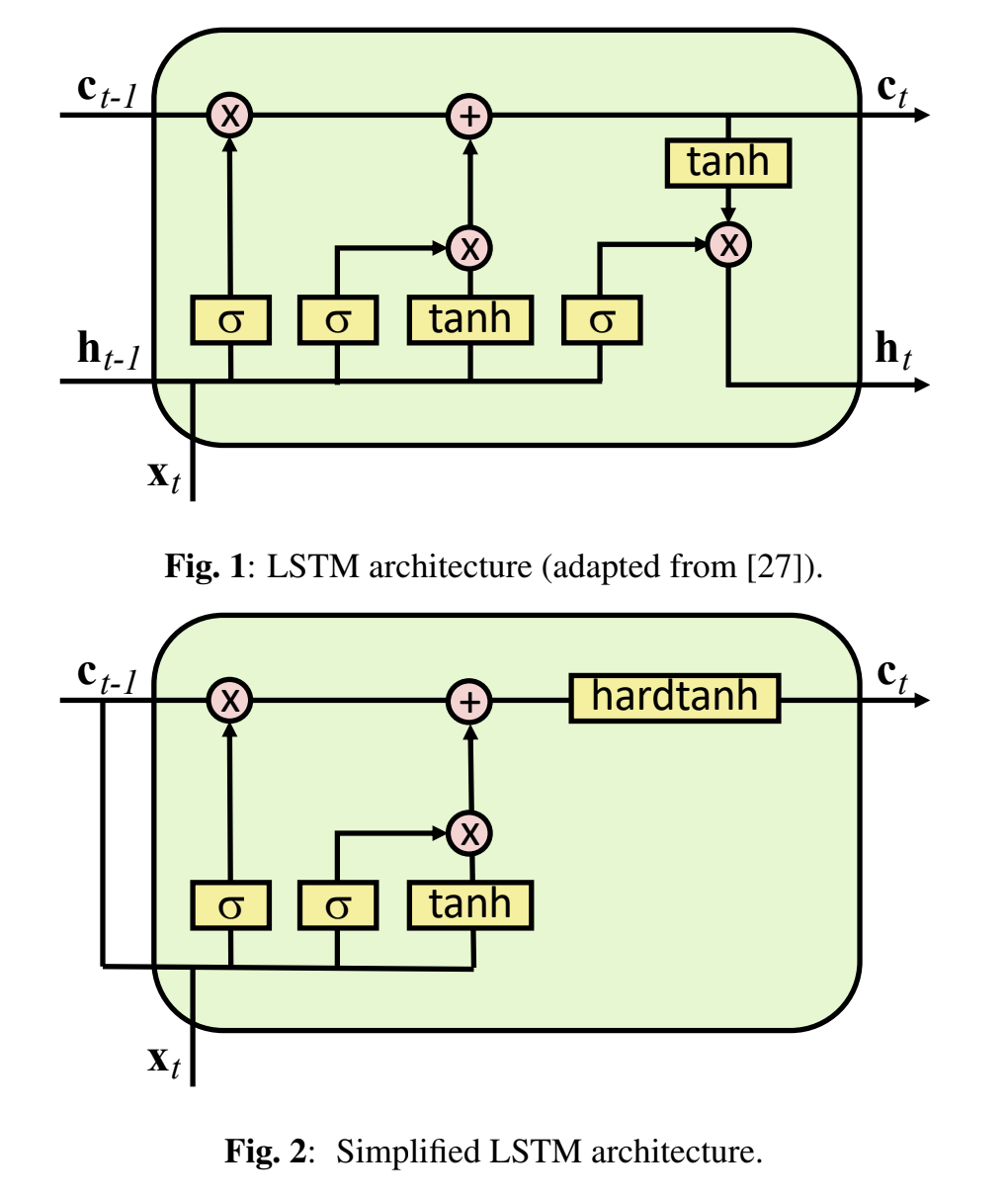
Simplified LSTMs for speech recognition
- The preprint is not publicly available yet (as on December 22, 2019), but I requested George Saon (the first author) to send me the paper. He kindly obliged.
- The authors propose a simpler variant of LSTMs which performs better with 25% fewer parameters. This really brings into question the efficiency of LSTMs, which are the most popular RNN architecture for ASR.
- From earlier research, it has been found that it is important to keep the input gate and forget gate separatte, and the output gate is the least useful.
- The key difference in the simplified variant is shown in the following figure from the paper. Note that there are no hidden states, only cell states. In experiments on the Switchboard 300 corpus, simplified LSTMs outperformed LSTMs and GRUs.
Adaptation methods for ASR
Speaker adaptation
-
Speaker adaptive training using model agnostic meta learning
- This paper models SAT as a meta-learning problem. For an adapted model, the loss of the meta-learner can be expressed as:
where $\mathcal{D}$ consists of tuples of adaptation data.
- Gradient descent is used to optimise the parameters $\Phi$ of the adaptation function.
- Conventionally for model-based adaptation, a copy of the speaker-dependent weights is maintained and optimised for each speaker separately. In this paper, however, a meta-learning approach is used in order to find a good initialisation for speaker-dependent weights by training jointly with acoustic model training.
-
Embeddings for DNN speaker adaptive training
- This paper uses speaker embeddings for speaker adaptive training of acoustic models (i-vectors are used for this purpose in Kaldi recipes).
- They investigate i-vectors, x-vectors, and deep CNN-based embeddings for adaptation. Furthermore, they explore different ways to incorporate the embeddings in the acoustic model:
- Control network: Element-wise scaling and bias parameters are obtained through a network and used to normalize the input. A skip connection is also added so that the normalization can be performed at several layers in the network.
- Control layer: To reduce parameters in the control network, we apply a linear transformation on the embedding (with or without the input features) by passing through a single layer. This is similar to the LDA layers used in Kaldi.
- Control vector: This is similar to control layer, but the weight matrix for the transformation is constrained to be a diagonal matrix.
- Control variable: A single scaling factor is used with the embedding and added to the input features.
- Utterance-level i-vectors and deep CNN embeddings perform similarly. X-vectors perform worse than both (this is consistent with some experiments I performed earlier this year). Also, control layers are the best way to incorporate these embeddings in acoustic model training.
Acoustic model adaptation
-
Acoustic model adapatation from raw waveforms with Sincnet
- The paper proposes a method to use SincNet layers to adapt an acoustic model trained on adult speech to children’s speech. In SincNet, the CNN filters learned from raw time-domain signals are constrained, by requiring each kernel to model a rectangular band-pass filter.
- By adapting the cut-off frequencies and the gains of the filters in the SincNet layer, it makes it well suited for speaker adaptation, since the lower layers carry more speaker information.
- Using a model trained on AMI, this adaptation technique improves the WER from 68% to 30% on PF-Star (children’s speech corpus).
-
Online batch normalization adaptation for automatic speech recognition
- The paper is not available publicly yet. The authors propose a linear interpolation between the batch parametters and the sample parameters for mean and variance normalization in the case on online adaptation.