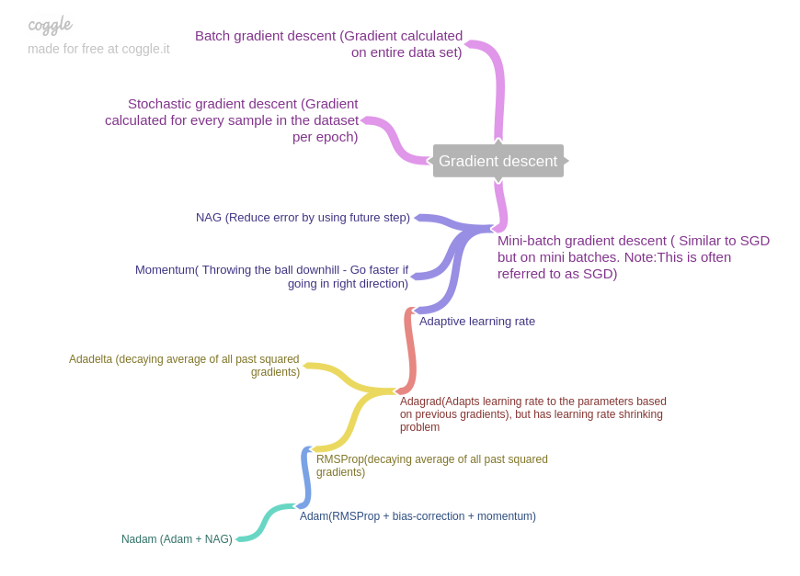
The above diagram is taken from this forum post.
I just finished reading Sebastian Ruder’s amazing article providing an overview of the most popular algorithms used for optimizing gradient descent. Here I’ll make very short notes on them primarily for purposes of recall.
Momentum
The update vector consists of another term which has the previous update vector (weighted by $\gamma$). This helps it to move faster downhill — like a ball.
\[v_t = \gamma v_{t-1} + \eta \nabla_{\theta}J(\theta)\]Nesterov accelerated gradient (NAG)
In Momentum optimizer, the ball may go past the minima due to too much momentum, so we want to have a look-ahead term. In NAG, we take gradient of future position instead of current position.
\[v_t = \gamma v_{t-1} + \eta \nabla_{\theta}J(\theta - \gamma v_{t-1})\]Adagrad
Instead of a common learning rate for all parameters, we want to have separate learning rate for each. So Adagrad keeps sum of squares of parameter-wise gradients and modifies individual learning rates using this. As a result, parameters occuring more often have smaller gradients.
\[\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{G_t +\epsilon}} \odot g_t\]RMSProp
In Adagrad, since we keep adding all gradients, gradients become vanishingly small after some time. So in RMSProp, the idea is to add them in a decaying fashion as
\[\mathbb{E}[g^2]_t = \gamma \mathbb{E}[g^2]_{t-1} + (1-\gamma)g_t^2\]Now replace $G_t$ in the denominator of Adagrad equation by this new term. Due to this, the gradients are no more vanishing.
Adam (Adaptive Moment Estimation)
Adam combines RMSProp with Momentum. So, in addition to using the decaying average of past squared gradients for parameter-specific learning rate, it uses a decaying average of past gradients in place of the current gradient (similar to Momentum).
\[\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v_t}+\epsilon}}\hat{m}_t\]The $\hat{}$ terms are actually bias-corrected averages to ensure that the values are not biased towards 0.
Nadam
Nadam combines RMSProp with NAG (since NAG is usually better for slope adaptation than Momentum. The derivation is simple and can be found in Ruder’s paper.
In summary, SGD suffers from 2 problems: (i) being hesitant at steep slopes, and (ii) having same learning rate for all parameters. So the improved algorithms are categorized as:
- Momentum, NAG: address issue (i). Usually NAG > Momentum.
- Adagrad, RMSProp: address issue (ii). RMSProp > Adagrad.
- Adam, Nadam: address both issues, by combining above methods.
Note: I have skipped a discussion on AdaDelta in this post since it is very similar to RMSProp and the latter is more popular.