Neural transducers are the most popular ASR modeling paradigm in both academia and industry. Since I could not attend InterSpeech 2023 in person, I decided to sift through the archive and find all papers which have the word “transducer” in their title. I found 21 papers, and in this post, I will try to summarize (and categorize) them. My hope is that this will give readers an idea about what is currently being done with transducers, and what the future might hold for them.
Background
I have previously written a short Twitter thread about them, but let me quickly get you up to speed on some basics.
Roughly speaking, there are 3 popular “end-to-end” ASR modeling paradigms currently in use:
- Connectionist Temporal Classification (CTC)
- Attention-based encoder-decoders (AED)
- Transducers (or RNN-T or Transformer-T)
CTC is the oldest of the three, and was introduced in 2006 by Alex Graves et al. in Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. It allows streaming models, but makes two limiting assumptions:
- The output sequence must be shorter than the input sequence.
- Output units at each time step are conditionally independent given the input.
AEDs were introduced in 2015 by Jan Chrowski et al. in Attention-Based Models for Speech Recognition. They are more flexible than CTC in the sense that they forego the 2 assumptions, but are not streaming models, since the entire input needs to be encoded first to start decoding. They also do not provide a time alignment between the input and output sequence, which is often useful for ASR.
Transducers were introduced in 2012 by Alex Graves et al. in Sequence Transduction with Recurrent Neural Networks. They provide the best of both worlds: they are streaming models, and they provide a time alignment between the input and output sequence. They are also more flexible than CTC since they can be used to model arbitarily long input and output sequences, and do not make any conditional independence assumptions.
Here is an overview diagram copied from this paper by Jinyu Li:
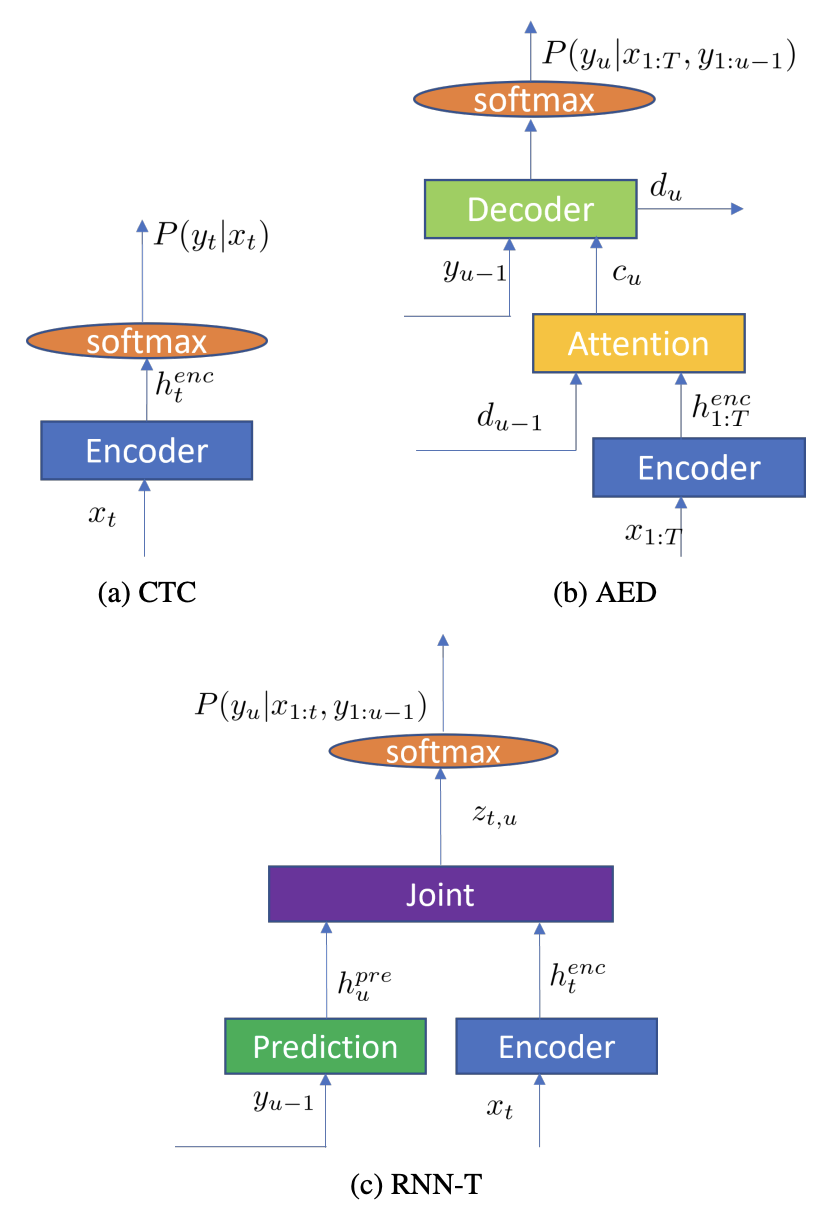
With this background, let us now look at the papers. I have categorized them into:
- Improving transducer-based ASR performance
- Fast and efficient inference
- Contextualization
- Domain adaptation
- Transducers for non-ASR tasks
Improving transducer-based ASR performance
The first category of papers includes those which propose strategies to improve the general ASR performance of transducer models.
1. Data augmentation
Cui et al. 1 used length perturbation, which randomly drops or inserts frames in the input acoustic sequence. Additionally, they randomly quantize the input features between the minimum and maximum values. Overall, the three methods result in WER improvement from 7.0% to 6.3% on SwitchBoard and CallHome test sets.
2. Training objective
Cui et al. 1 propose training the transducer using label smoothing. In general, label smoothing is used to prevent overconfidence when using cross-entropy based training. Here, since the RNN-T loss is a sequence loss, the authors found that local label smoothing (i.e. applied per frame) degrades the model. Instead, they applied an approximate sequence-level smoothing by sampling a random negative sequence and using this sequence as the negative target.
In the last few years, transducer training has become reasonably stable and efficient, thanks in part to methods such as function merging and lattice pruning using external or internal alignments. A consequence of lattice pruning is that a streaming model also learns to avoid pushing token prediction to the future (in fact, the AR-RNNT method was developed to improve token emission delay). An et al. 2 propose a new method called boundary aware transducer (BAT), which can be categorized as falling into this latter class of methods. Similar to pruned RNN-T, BAT also prunes the lattice using an internal alignment mechanism. The difference is that while the former obtains these pruning bounds using a simple additive joiner, BAT obtains them through a continuous integrate-and-fire (CIF) module on top of the encoder. The authors show that it retains CER compared to original RNN-T, while improving emission time and peak memory usage. However, they did not compare the CER performance with pruned RNN-T.
3. Modeling
Li et al. 3 propose phonetic multi-target units (PMU) modeling. The idea is to combine BPE-based subwords with previously proposed PASM units in order to improve output units. PASM units are more pronunciation driven but tend to be small, which has the effect the larger units cannot be modeled directly. The authors propose several ways of doing multi-target training, such as simply predicting the units in different branches, or using self-conditioned CTC with the PASM targets in the intermediate layers.
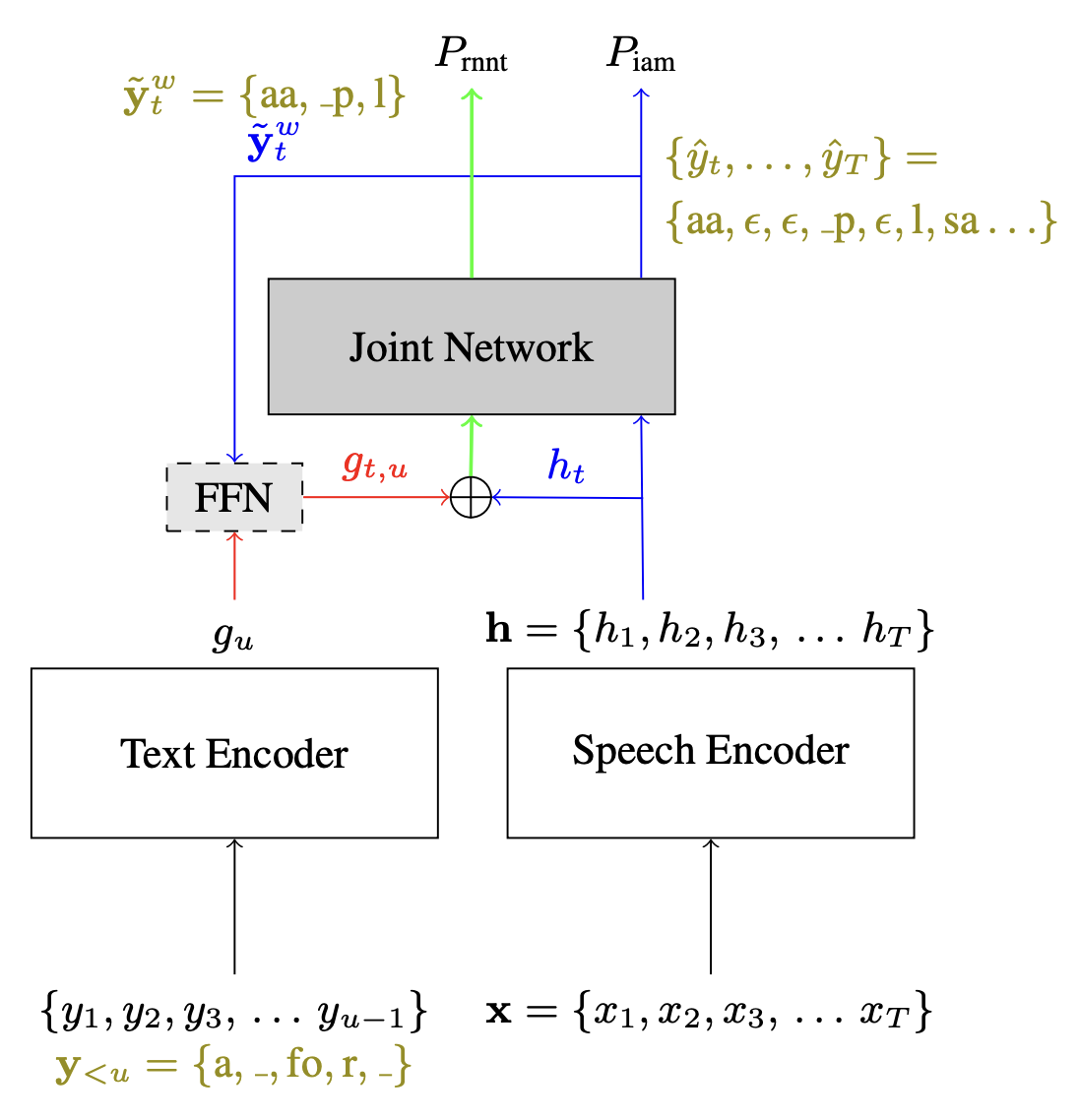
Unni et al. 4 propose acoustic lookahead. They found that streaming RNN-T models often hallucinate words, and attribute this to speech independent encoding of text. To fix this, they use future acoustic frames to condition the text encoding in the prediction network. This conditioning is done by first predicting the most likely next tokens based only on the acoustic features (i.e., by setting the predicition network output to $\mathbf{0}$), and then combining the prediction with the prediction network output through a feed-forward layer. This simple technique shows improvements on LibriSpeech and CommonVoice datasets. Here is a diagram from the paper showing the lookahead mechanism:
Sudo et al. 5 propose a variation of the popular cascaded encoders for online + offline modeling of transducer-based ASR. Instead of stacking the online and full-context encoders in sequence, they apply them in parallel, and then stack the encoder representations for computing the loss from the offline branch. The motivation is to avoid error accumulation that often happens in cascaded structures. For the online encoder, they also use dynamic block training, which increases variability of the online encoder’s representations, and also allows flexible block size selection during inference.
4. Better decoding methods
Sudo et al. 5 also proposed a joint one-pass time-synchronous beam search to improve the offline decoding performance using the online encoder. The idea is to generate a set of hypotheses using the offline decoder, and then obtain scores for these hypotheses using the online branch. This method was shown to improve the CER on the CSJ dataset, for both online and offline models.
The popular beam search methods for transducers, as described in this paper, are:
- Default beam search (proposed by Graves et al.), which allows unrestricted expansion along both T and U axes.
- Label synchronous decoding (such as ALSD), which runs along the U axes and constrains the label sequence to be shorter than the input sequence.
- Time synchronous decoding, which runs along the T axes and allows at most a fixed number of labels to be emitted per time step. These include methods such as one-step or k-step constrained beam search.
In Praveen et al. 6, the authors propose a new label-synchronous decoding method called prefix search decoding (inspired from similar decoding methods for CTC). In this method, the probability of outputting a token is obtained by summing the probabilities over all time steps, instead of only summing inside the beam-pruned lattice. This method was shown to provide a small improvement on LibriSpeech, but degraded WER on AMI-IHM.
Fast and efficient inference
Since the transducer is commonly used in industrial ASR systems, there is a lot of interest in making the inference fast and efficient. In general, inference time is impacted by three factors of latency:
- Input latency: For example, if future context or lookahead is used to predict the token at current time step.
- Computational latency: This is decided by the neural network and the decoding algorithm.
- Modeling latency:: The model may push its predictions to the future due to how the loss is computed.
In total, I found 3 papers at the conference which propose methods for fast inference. Of these, two are related to improving the computational latency, and one is related to improving the modeling latency.
Li et al. 7 propose adjacent token merging. The idea is that most of the intermediate encoder computations are redundant since adjacent tokens are often highly similar. The authors subsample intermediate layers in the transformer encoder by merging adjacent frames when they are similar, as measured by the cosine similarity between their key embeddings. This simple technique results in 2x speedup in inference time, with only minor WER degradation.
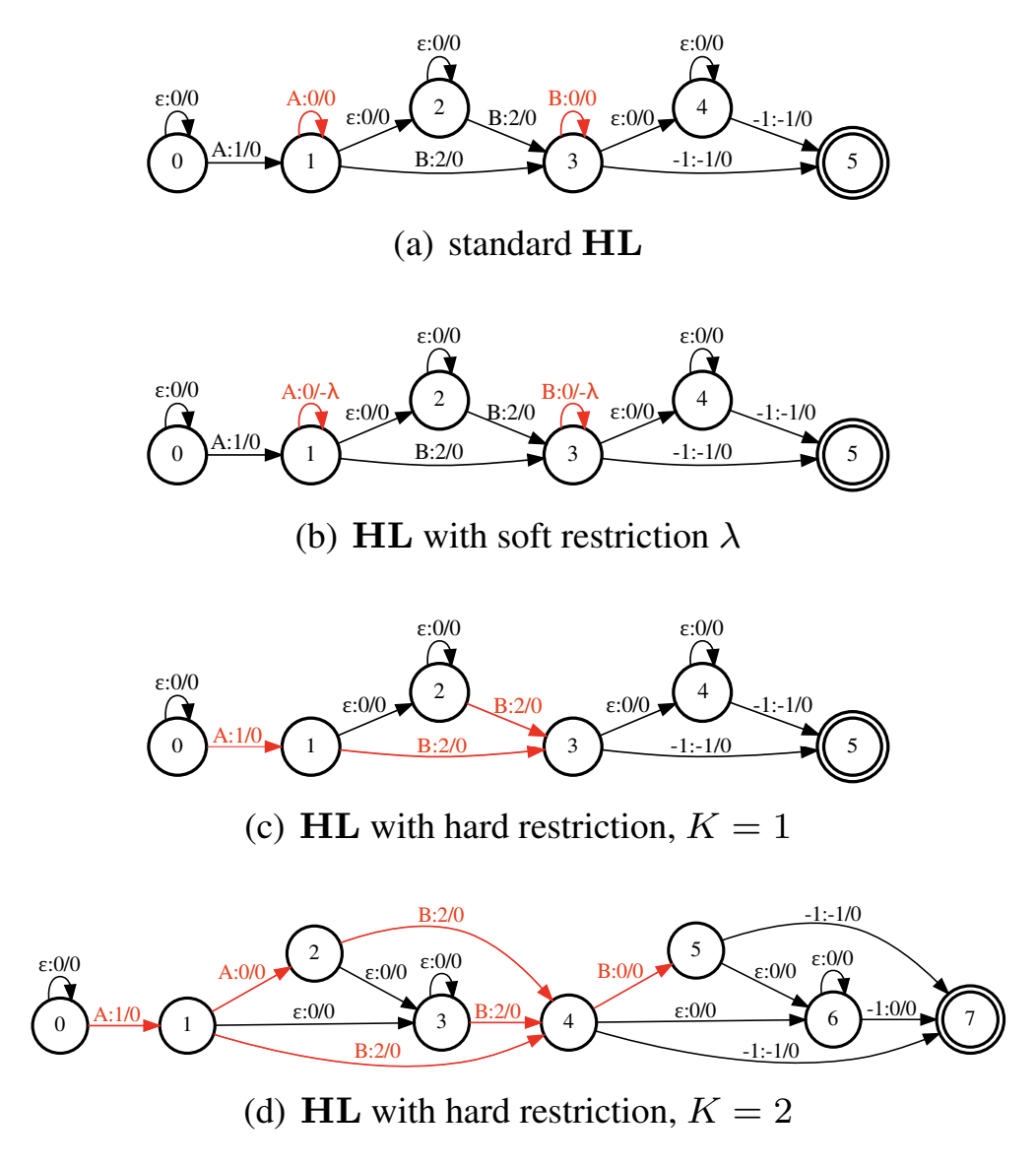
Yang et al. 8 propose frame skipping in the transducer using a blank-regularized CTC. The idea is that if an auxiliary CTC head is trained along with the transducer, it can be used to skip decoding frames where it predicts a blank token. This idea is not new; in fact, it has earlier been used in these papers. The difference here is that the authors actively try to make the CTC predictions “peaky” to ensure that more frames can be skipped. This is done by adding soft or hard constraints on the CTC graph during training.
Recall that the CTC loss can be efficiently computed through the forward algorithm on the CTC graph composed with the linear chain FST corresponding to the transcript. The original CTC allows repetitions of tokens through self-loops on the nodes. The authors apply a soft constraint by adding a penalty (i.e., a negative weight) on the self-loops for the non-blank tokens. Alternatively, a hard constraint can be applied by removing the self-loops for the non-blank tokens, and instead unfolding the graph for the desired number of repetitions. On the LibriSpeech corpus, both methods result in ~4x speedup (measured by RTF) without any degradation in WER.
The following figure taken from the paper shows the WFSTs for the $HL$ corresponding to the original CTC and the modified versions that include soft and hard restrictions:
Tian et al. 9 propose a Bayes risk transducer, which is intended to reduce the modeling latency. In general, when we train a transducer by minimizing the loss computed over the sum over all possible alignments, it does not penalize the model for pushing the predictions to the future. The authors propose that we can instead minimize a Bayes risk function which has a lower value for preferred paths, and higher for delayed paths. The loss function is defined using a standard Minimum Bayes Risk (MBR) formulation, and the key idea is to group the “risk function” among paths which have the same cost. It seems this method gives a good WER-RTF trade-off compared to training with the original transducer loss.
Additionally, the boundary-aware training method proposed by An et al. 2 also serves to improve the modeling latency, by pruning the delayed alignments during training.
Contextualization
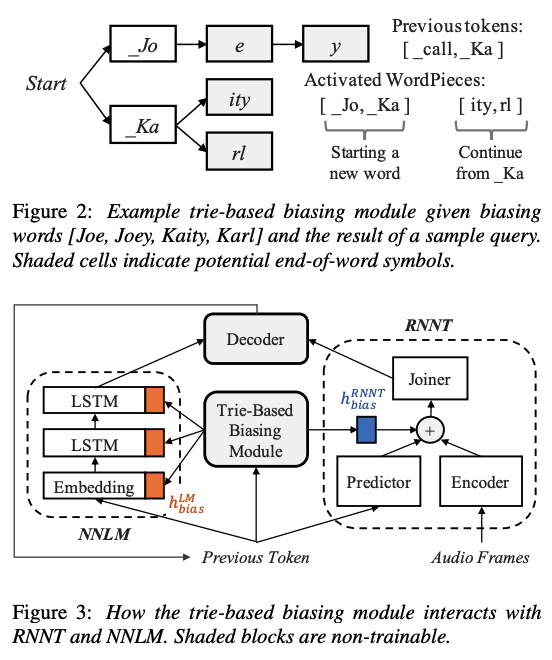
Now that transducers are well established in industry, there is a lot of interest in personalizing or contextualizing them. This was relatively easy to do in older ASR systems which used WFST based decoding, by boosting the unigram probabilities of in-context words in the decoding graph. However, since transducers are end-to-end neural models, it makes it more challenging to contextualize them. In general, “deep contextual biasing” methods are used to contextualize transducers, where the biasing is done by attending to a list of bias terms, usually in the prediction network. A popular method in this line of work is the trie-based contextual biasing proposed by the speech group at Meta, which is shown below:
Overall, there are 2 main problems in building such systems: (i) how to generate a good candidate list of bias words, and (ii) how to avoid over-biasing the transducer. The following methods were proposed at the conference to improve contextualization of transducers.
Xu et al. 10 propose adaptive contextual biasing (ACB). The authors suggested that always using a list of bias words degrades WER on common words. To alleviate this, they use a predictor entity detector module to identify if a named entity is present in the utterance, and use this to turn the biasing module on or off.
Harding et al. 11 also recognized the “over-biasing” problem, and propose methods to alleviate it specificially in the context of trie-based biasing. For this, they use these techniques:
- Instead of training the joiner from scratch, they freeze the pretrained model and use an adapter as the biasing module, similar to this work.
- They decouple the bias embeddings from the projection network hidden state, by factoring it out with a projection layer.
- Similar to Xu et al., they propose a method to turn the biasing module on or off. They use a slot-triggered biasing, where the predictor emits opening and closing entity tags where it detects a slot filler (similar to the entity prediction idea). The same group had another paper 12 describing the slot-triggered biasing method in more detail.
In previous works, it was found that contextual biasing works best when the bias list is compact and accurate. Yang et al. 13 propose a method to generate such a list, particularly for unified streaming and non-streaming transducer models. Their pipeline is best understood through the following figure (taken from the paper):
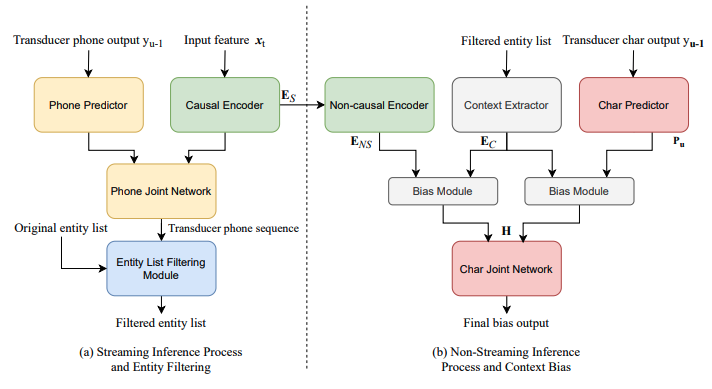
In summary, they use a phone-based predictor and joiner to filter out words which are unlikely, among the original entity list. This filtered list is then used for biasing in the regular character based predictor/joiner. The authors show that using this filtered list provides significant improvements compared to using the full list, although there is still a lot of room for improvement compared to using the oracle list.
Domain adaptation
Another popular area of research (related to personalization/contextualization) is domain adaptation. In general, a “domain” may be either acoustic or linguistic, and there are methods to adapt to both of these. The following papers at InterSpeech pertained to domain adaptation for transducers.
Huang et al. 14 propose text-only domain adaptation. The idea is to use an additional text encoder which can be considered a proxy for the audio encoder for the case that we don’t have any parallel audio. The method is best understood through the following diagram taken from the paper. In practice, most of the transformations are in the “shared” layer, so that the increase in model size is only marginal.
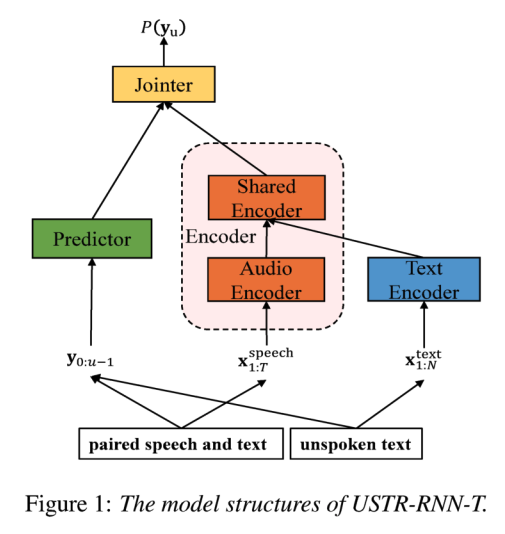
In conventional hybrid ASR systems, adapting to a new linguistic domain was performed by training a new language model, and pairing it with an existing acoustic model. Since transducers are not easily decomposable into acoustic and language models, the Hybrid Autoregressive Transducer (HAT) model was proposed to allow this decomposition. Briefly put, HAT estimates an “internal” language model (ILM) from the transducer, which can be subtracted from the posterior before adding the scores from an external language model. Lee et al. 15 propose a method to improve the estimation of this ILM. The authors suggest that the HAT algorithm is justified only when the sum of acoustic and language scores is close to the actual output score. Therefore, they add this term as an additional constraint using the MSE loss. The resulting model gives stable improvements compared to the original HAT model.
Finally, Li et al. 16 propose modular domain adaptation to handle all kinds of domains through the use of adapters. The authors found that by training per-domain FFN layers in the Conformer encoder, better performance can be achieved compared to training a single encoder for all domains. However, this is slightly discouraging since the FFN layer contains most of the parameters in the Conformer.
Transducers beyond simple ASR
Several groups are now starting to use transducers for things beyond regular single-speaker single-utterance ASR. Some of the candidates in this line of work include:
- Kanagawa et al. 17 used transducers for streaming voice conversion.
- Cui et al. 18 used transducers for long-form contextual ASR. Note that this is different from the contextualization methods described earlier, since the context here refers to the entire history of utterances transcibed so far.
- Moriya et al. 19 used transducers for target-speaker ASR.
- Mehta et al. 20 used transducers for TTS, by adding a normalizing flow on top of the transducer.
- Wang et al. 21 used transducers for multilingual ASR and translation.
I am not an expert in these areas, so I will not attempt to summarize these papers.
Summary
In summary, it seems there is less work now on improving the basic transducer model (either in terms of training efficiency or performance), which suggests that most groups have strong working implementations of the model. The focus now (similar to earlier this year at ICASSP) is on (i) making inference faster mainly by reducing redundancy, (ii) contextualizing the model for the speaker (e.g. for contact lists), and (iii) adapting the model to new domains. Finally, there is also growing interest in using transducers for tasks beyond simple ASR, such as combining them with TTS or speech translation.
References
-
Cui, X., Saon, G., Kingsbury, B. (2023) Improving RNN Transducer Acoustic Models for English Conversational Speech Recognition. Proc. INTERSPEECH 2023, 1299-1303, doi: 10.21437/Interspeech.2023-2207 ↩ ↩2
-
An, K., Shi, X., Zhang, S. (2023) BAT: Boundary aware transducer for memory-efficient and low-latency ASR. Proc. INTERSPEECH 2023, 4963-4967, doi: 10.21437/Interspeech.2023-770 ↩ ↩2
-
Li, L., Xu, D., Wei, H., Long, Y. (2023) Phonetic-assisted Multi-Target Units Modeling for Improving Conformer-Transducer ASR system. Proc. INTERSPEECH 2023, 2263-2267, doi: 10.21437/Interspeech.2023-97 ↩
-
Unni, V.S., Mittal, A., Jyothi, P., Sarawagi, S. (2023) Improving RNN-Transducers with Acoustic LookAhead. Proc. INTERSPEECH 2023, 4419-4423, doi: 10.21437/Interspeech.2023-2354 ↩
-
Sudo, Y., Muhammad, S., Peng, Y., Watanabe, S. (2023) Time-synchronous one-pass Beam Search for Parallel Online and Offline Transducers with Dynamic Block Training. Proc. INTERSPEECH 2023, 4479-4483, doi: 10.21437/Interspeech.2023-1333 ↩ ↩2
-
Praveen, K., Dhopeshwarkar, A.V., Pandey, A., Radhakrishnan, B. (2023) Prefix Search Decoding for RNN Transducers. Proc. INTERSPEECH 2023, 4484-4488, doi: 10.21437/Interspeech.2023-2065 ↩
-
Li, Y., Wu, Y., Li, J., Liu, S. (2023) Accelerating Transducers through Adjacent Token Merging. Proc. INTERSPEECH 2023, 1379-1383, doi: 10.21437/Interspeech.2023-599 ↩
-
Yang, Y., Yang, X., Guo, L., Yao, Z., Kang, W., Kuang, F., Lin, L., Chen, X., Povey, D. (2023) Blank-regularized CTC for Frame Skipping in Neural Transducer. Proc. INTERSPEECH 2023, 4409-4413, doi: 10.21437/Interspeech.2023-759 ↩
-
Tian, J., Yu, J., Chen, H., Yan, B., Weng, C., Yu, D., Watanabe, S. (2023) Bayes Risk Transducer: Transducer with Controllable Alignment Prediction. Proc. INTERSPEECH 2023, 4968-4972, doi: 10.21437/Interspeech.2023-1342 ↩
-
Xu, T., Yang, Z., Huang, K., Guo, P., Zhang, A., Li, B., Chen, C., Li, C., Xie, L. (2023) Adaptive Contextual Biasing for Transducer Based Streaming Speech Recognition. Proc. INTERSPEECH 2023, 1668-1672, doi: 10.21437/Interspeech.2023-884 ↩
-
Harding, P., Tong, S., Wiesler, S. (2023) Selective Biasing with Trie-based Contextual Adapters for Personalised Speech Recognition using Neural Transducers. Proc. INTERSPEECH 2023, 256-260, doi: 10.21437/Interspeech.2023-739 ↩
-
Lu, Y., Harding, P., Mysore Sathyendra, K., Tong, S., Fu, X., Liu, J., Chang, F.-J., Wiesler, S., Strimel, G.P. (2023) Model-Internal Slot-triggered Biasing for Domain Expansion in Neural Transducer ASR Models. Proc. INTERSPEECH 2023, 1324-1328, doi: 10.21437/Interspeech.2023-1010 ↩
-
Yang, Z., Sun, S., Wang, X., Zhang, Y., Ma, L., Xie, L. (2023) Two Stage Contextual Word Filtering for Context Bias in Unified Streaming and Non-streaming Transducer. Proc. INTERSPEECH 2023, 3257-3261, doi: 10.21437/Interspeech.2023-1171 ↩
-
Huang, L., Li, B., Zhang, J., Lu, L., Ma, Z. (2023) Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer. Proc. INTERSPEECH 2023, 386-390, doi: 10.21437/Interspeech.2023-1313 ↩
-
Lee, K., Kim, H., Jin, S., Park, J., Han, Y. (2023) A More Accurate Internal Language Model Score Estimation for the Hybrid Autoregressive Transducer. Proc. INTERSPEECH 2023, 869-873, doi: 10.21437/Interspeech.2023-213 ↩
-
Li, Q., Li, B., Hwang, D., Sainath, T., Mengibar, P.M. (2023) Modular Domain Adaptation for Conformer-Based Streaming ASR. Proc. INTERSPEECH 2023, 3357-3361, doi: 10.21437/Interspeech.2023-2215 ↩
-
Kanagawa, H., Moriya, T., Ijima, Y. (2023) VC-T: Streaming Voice Conversion Based on Neural Transducer. Proc. INTERSPEECH 2023, 2088-2092, doi: 10.21437/Interspeech.2023-2383 ↩
-
Cui, M., Kang, J., Deng, J., Yin, X., Xie, Y., Chen, X., Liu, X. (2023) Towards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems. Proc. INTERSPEECH 2023, 2223-2227, doi: 10.21437/Interspeech.2023-552 ↩
-
Moriya, T., Sato, H., Ochiai, T., Delcroix, M., Ashihara, T., Matsuura, K., Tanaka, T., Masumura, R., Ogawa, A., Asami, T. (2023) Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data. Proc. INTERSPEECH 2023, 899-903, doi: 10.21437/Interspeech.2023-2280 ↩
-
Mehta, S., Kirkland, A., Lameris, H., Beskow, J., Székely, É., Henter, G.E. (2023) OverFlow: Putting flows on top of neural transducers for better TTS. Proc. INTERSPEECH 2023, 4279-4283, doi: 10.21437/Interspeech.2023-1996 ↩
-
Wang, P., Sun, E., Xue, J., Wu, Y., Zhou, L., Gaur, Y., Liu, S., Li, J. (2023) LAMASSU: A Streaming Language-Agnostic Multilingual Speech Recognition and Translation Model Using Neural Transducers. Proc. INTERSPEECH 2023, 57-61, doi: 10.21437/Interspeech.2023-2004 ↩