Spoken Dialog Systems (SDS) have become very popular recently, especially for goal completion tasks on mobile devices. Also, with the increasing use of IoT devices and their associated assistants like Alexa, Google Home, etc., systems that can converse with users in natural language are set to be the primary mode of human-computer interaction in the coming years.
Early SDSs used to be extremely modular, with components such as automatic speech recognition, natural language understanding, dialog management, response generation, and speech synthesis, each trained separately and then combined. For the last few years, especially after neural models gained popularity in language models and machine translation, researchers are slowly but surely moving towards more end-to-end approaches. Very recently, most of the dialog systems proposed in conferences all seem to be built around reinforcement learning frameworks.
Although they are critical in industry, SDSs have traditionally been notoriously difficult to evaluate. This is because any evaluation strategy associated with them needs to have at least the following features.
- It should provide an estimate of how well the goal is met.
- It should allow for comparative judgement of different systems.
- It should (ideally) identify factors that can be improved.
- It should discover trade-offs or correlations between factors.
For a long time, the most prominent evaluation scheme for SDSs was PARADISE (Walker’97), developed at AT&T labs.
PARADISE: PARAdigm for DIalog System Evalutation
The Paradise scheme comprises of 2 objectives:
- What does the agent accomplish? i.e., task completion
- How is it accomplished? i.e., agent behavior
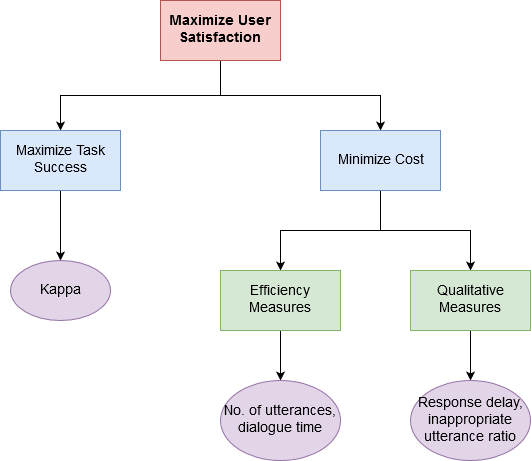
For quantifying these objectives, the task is represented in the form of an Attribute Value Matrix (AVM), which consists of the information that must be exchanged between the agent and the user during the dialogue, represented as a set of ordered pairs of attributes and their possible values. Essentially, this is a confusion matrix between attributes in the actual dialogue and attributes in the expected dialogue.
Once the AVM is available, the task completion success is computed by a metric $\kappa$ defined as
\[\kappa = \frac{P(A)-P(E)}{1-P(E)}\]where $P(A)$ is the proportion of times that the actual dialogue agrees with the scenario keys, and $P(E)$ is the expected proportion of times for the same. If $M$ is the matrix, then
\[P(E) = \sum_{i=1}^n \left( \frac{t_i}{T} \right)^2\]where $t_i$ is the sum of frequencies in column $i$, and $T$ is the sum of frequencies in $M$. $P(A)$ is given as
\[P(A) = \sum_{i=1}^n \frac{M(i,i)}{T}\]Since $\kappa$ includes $P(E)$, it inherently includes the task complexity as well, thereby making it a better metric for task completion than, say, transaction success, concept accuracy, or percent agreement.
For measuring the second objective, i.e., agent behavior, all the AVM attributes are tagged with respective costs. Some examples of cost attributes are: number of user initiatives, mean word per turn, mean response time, number of missing/inappropriate responses, number of errors, etc. Thereafter, the final performance is defined as
\[P = (\alpha \mathcal{N}(\kappa)) - \sum_{i=1}^n (w_i \mathcal{N}(c_i))\]Here, $\mathcal{N}$ is some Z-score normalization factor, such as simple normalization based on mean and standard deviation.
Although PARADISE was an important evaluation scheme for evaluating older statistical SDS models, I haven’t seen it used in any of the recent papers on the subject. A major factor for this is probably the choice of the regression coefficients (costs and coefficient for Kappa), which would greatly affect the performance statistic.
Schemes in Recent Papers
For the last couple years, most papers on SDSs propose end-to-end neural architectures. As such, they prefer an evaluation scheme based on a corpus of dialogues divided into training, validation, and development sets.
Data collection
Amazon Mechanical Turk (MT), which is a crowdsourcing website, is the most popular method for collecting data. Peng’17, Li’17, and Wen’16 all use Amazon MT to source their training dialogue sets. Furthermore, the protocol used for this is usually the Wizard-of-Oz scheme.
The Wizard-of-Oz protocol: In this scheme, a user converses with an agent, which he believes is autonomous. However, there is actually a human in the loop (called a “wizard”) which controls some key features of the agent which require tuning. The protocol is implemented as follows.
- A metric (e.g., task completion rate) is selected to serve as the objective function.
- Some particular features, called the “repair strategy,” are varied to best match the desired performance claim for the metric.
- All other input, output are kept constant through the interface.
- The process is repeated using different wizards.
In Wen’16, the authors further expediated this protocol by parallelizing it on Amazon MT, such that there are multiple users and wizards working simultaneously on single-turn dialogues.
Task completion usually involved slot filling as an intermediate objective. As such, several “informable slots” (e.g., food, price range, area, for a restaurant search system) and “requestable slots”(e.g., address, phone, postal code) are identified. Users are provided with the keys for the informable slots and wizards are provided with keys for the requestable slots.
In some cases, like Liu’18 and Peng’17, user simulators are also used to create such a corpus of dialogues. An implementation of such a system can be found here. For Liu’18, the authors further used a public dataset (DSTC) for corpus-based training.
Automatic evaluation
Automatic evaluation metrices may be unsupervised or supervised in nature. Liu’17 summarizes several unsupervised schemes for evaluation, and I list them here.
Word overlap based metrics
These include BLEU, ROUGE, and METEOR, and are inspired from machine translation tasks. I have previously described all of these metrics in another blog post.
Embedding based metrics
These are based on the word embeddings (skip-gram, GloVe, etc.) of the actual response and the expected response. Some of them are:
- Greedy matching
- Embedding average
- Vector extrema
Please refer to the linked paper for details of these metrics. They are conceptually very simple so I won’t describe them here.
A problem with both of these techniques is that they may only be suitable for task completion dialog systems, where there are only a few expected responses. Any open-world dialog will necessarily beat the metric, e.g.
User: Do you want to watch a movie today?
Gold-standard: Yeah, let’s catch the new Bond film.
Actual: No, I am busy with something.
For this reason, several other metrics are employed, such as task success rate, average reward (+1 for each slot filled correctly), average number of turns, entity matching rate, prediction accuracy, etc.
Human evaluation
Most importantly though, all researchers agree that human evaluation can never be replaced by automatic evaluation metrics. Usually, several human users are asked to test a trained system with goal-oriented dialogues, and at the end of the dialogue, they are asked to rate it on several criteria such as:
- Task completion success
- Comprehension
- Naturalness
To avoid extreme scores (due to bias etc.), inter-user agreement is calculated using the Kappa value, and only those users with $\kappa > 0.2$ are retained in the final measure. Their scores are then matched against scores from the automatic evaluations by computing correlation coefficients such as Spearman’s or Pearson’s (like in Liu’16).
Key Takeaways
From this entire literature survey, I have extracted the following key points to note if you are working to build a task-oriented dialog system and want to evaluate it:
- Choose one specific domain, e.g., restaurant search.
- Use either DSTC (or an equivalent large corpus of dialogues), or use Amazon MT to create one for your task.
- Train your model on the dataset created above.
- Use a word overlap based and a few task completion based metrics for automatic evaluation statistics. Compare with at least a few popular neural baselines. RL frameworks with LSTMs are in vogue these days, I suppose.
- Definitely do human evaluation for your method.