When I was browsing through research groups for my grad school applications, I came across some interesting applications of new deep learning methods in a multimodal setting. ‘Multimodal,’ as the name suggests, refers to any system involving two or more modes of input or output. For example, an image captioning system provides images as input and expects a textual output. Similarly, speech-to-text, descriptive art, video summarization, etc., are all examples of multimodal objectives. In this article, I will discuss 3 recent papers from Mohit Bansal (who joined UNC last year), based on album summarization, video captioning, and image captioning (with a twist).
Creating a story from an album
Given an album containing several images (which may or may not be similar), the task of Visual Storytelling is to generate a natural language story describing the album. In this EMNLP ’17 paper1, the task is decomposed into 3 steps:
- Album encoder: Encode the individual photos in the album to form photo vectors
- Photo selector: Select a small number of representative photos.
- Story generator: Compose a coherent story from the selected photo vectors.
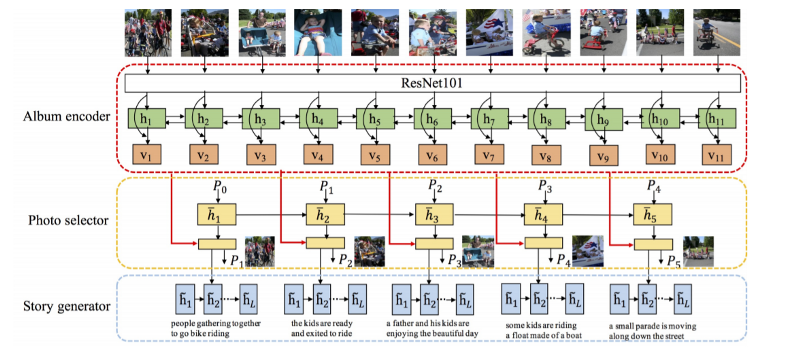
For each of these three components, the paper uses a hierarchically-attentive RNN. The first component is similar to an embedding layer in a text classification setting, wherein a lookup table assigns some pretrained vectors to each word and then an RNN is applied to add sentence-level information to each word vector. In a similar fashion in this paper, the initial embeddings for each image are obtained using a pretrained ResNet101 layer, and then a bidirectional RNN with GRU cells is used to add information pertaining to the entire album in every image embedding.
In the Photo Selector stage, the selection is treated as a latent variable since we only have end-to-end ground truth labels. As such, we use soft attention to output $t$ probability distributions over all the images in the album, where $t$ is the number of summary images required, i.e., each image has $t$ probabilities associated with it. For this purpose, a GRU takes the previous $p$ and the previous hidden state h as input and outputs the next hidden state. We use a multilayer perceptron with sigmoid activation to fuse the hidden state with the photo vector and obtain the soft attention for the particular image.
\[h_t = GRU_{select}(p_{t-1},h_{t-1}) \\ p(y_{a_i}(t)=1) = \sigma(MLP([h_t,v_i]))\]Finally, we can obtain $t$ weighted album representations by taking the weighted sum of the photo vectors with the corresponding probability distributions. Each of these vectors is then used to decode a single sentence. For this purpose, a GRU takes the joint input of the album vector at step $t$, the previous word embedding, and the previous hidden state, and outputs the next hidden state. We repeat this for $t$ steps, thus obtaining the required album summary.
How do we define loss in such a setting? First, since we already know the correct summary sentences, we can define a generation loss which is simply the sum of negative log likelihoods of the correct words. However, in addition to the words being similar, the story should be temporally coherent, i.e., the sentences themselves should be in a specific order. For this purpose, we apply a max-margin ranking loss as:
\[h_t = GRU_{select}(p_{t-1},h_{t-1}) \\ p(y_{a_i}(t)=1) = \sigma(MLP([h_t,v_i]))\]The total loss is just a linear combination of these two losses. This provides a framework for end-to-end training for the system.
Captioning videos using multi-task learning
It seems multitask learning was under the spotlight in ACL ’17. Two semantic parsing papers I discussed in yesterday’s blog were both based on this paradigm, and so is this one.
At this point, I would like to clarify the difference between transfer learning and multitask learning by quoting directly from this answer on ResearchGate:
Multi-task learning can be seen as one type of transfer learning, where the information to transfer is some inner representation/substructure of the models under consideration, or the relevant features for a prediction, and where all the target tasks use the same data samples, but predict different target features for these (e.g. Part Of Speech tagging and Named Entity Recognition for natural language processing tasks).
Transfer Learning, on the other hand, would be the very general problem setting, where the “what” to transfer (representation, model substructures, data samples, parameter priors, …), the concurrency of learning (one or multiple target tasks using one or multiple source tasks, or learning several tasks jointly), the differences in domain (same data or different samples, samples from same or different/related distribution, same or partially different input features) and prediction problem (same target feature or different target features/tasks, same conditional or different/related conditional) are characteristics identifying the subclass of transfer learning problem, and maybe the approach taken to address this problem.
A more formal definition can be found here. Essentially in multitask learning, all the tasks are learnt simultaneously, whereas in transfer learning, the knowledge from one task is used in another. Now that the terminology is clear, let us look at the tasks and the model used.
The objective in this paper is video captioning, and the co-learnt tasks are video prediction and language entailment generation. It is arguably difficult to obtain large amounts of annotated data for a video prediction task, and hence learning from other tasks is especially relevant in this context.
Video prediction refers to the task of predicting the next frame in a video given a sequence of frames. Recognizing textual entailment (RTE), means identifying the logical relationship between two sentences, i.e., whether a premise and hypothesis follow entailment, contradiction, or independence. Knowledge transfer from a video prediction setting helps the model learn the temporal flow of information in a video, while learning from an RTE setting helps it in logically infering a caption from the video. This is the rationale behind using these tasks for the multi-task learning framework.
The overall architecture of the system is given below.
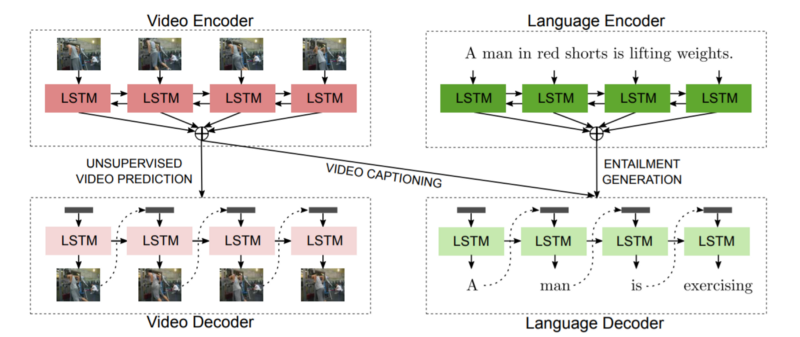
For each subsystem, the paper uses a simple attention-based bidirectional LSTM for the encoding and decoding purposes. This is a fine example of how a simple sequence-to-sequence block can be leveraged in different settings to perform interesting tasks.
Puns in image captions
Humor is difficult to capture or create in general. Heterographic homophones (words with different spelling but similar sound) are often used by cartoonists to add subtext to illustrations.

In this paper2, the authors have proposed 2 different methods to generate “punny” captions for images, namely a Generation model, and a Retrieval model.
The Generation model works as follows:
- The first step is tagging. We identify the top 5 objects in the given image using an Inception-ResNet-v2 model trained on ImageNet. We also get the words from a simple caption generated for the image using a Show-and-Tell architecture. The objects and the words together are considered as tags for pun generation.
- We then generate a vocabulary of puns by mining the web and selecting all pairs of words with an edit distance of 0 based on articulatory features.
- From this pun vocabulary, we filter those puns where at least one of the homophones is related to the image in question.
- During the caption generation, at specific time steps, the model is forced to produce a phonological counterpart of a pun word associated with the image. The decoder generates next words based on all previously generated words.
- To solve the issue of non-grammatical sentences due to puns later in the sentence, two models are trained to decode the image in both forward and reverse directions.
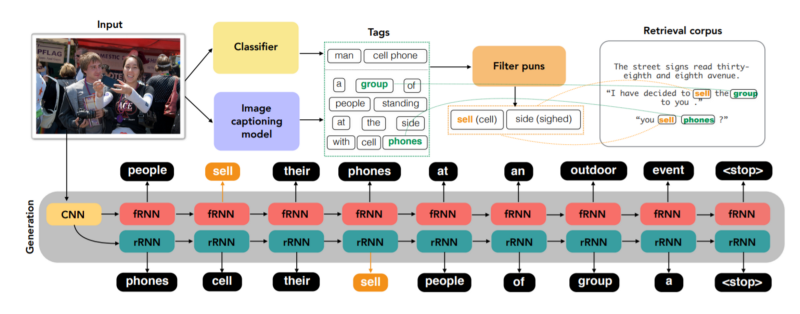
The Retrieval model, on the other hand, tries to find relevant captions from a prebuilt corpus of captions. This is an entirely deterministic model which requires two conditions to be satisfied:
- The caption must contain the counterpart of the pun word present in the image so that incongruity is attained.
- The caption must be contextually relevant to the image, i.e., it must contain at least one of the “tagged” words that we found earlier.
Finally, the captions obtained from both models are pooled together and ranked by taking their log-probability score with respect to the original caption generated from the simple image captioning model. Non-maximal suppression is applied to remove captions which are similar to a higher-ranked caption, and the top 3 such obtained are retained.
From these examples of multimodal systems, we see that simple sequence-to-sequence models work satsifactorily if used in conjuction with intelligent frameworks such as multitask learning or transfer learning, as is the trend in recent days. A cool thing is that reading about the various transfer learning approaches for this and the previous post has helped me come up with a new solution for a project that I have been working on. More on that later!
Conference on Empirical Methods in Natural Language Processing*. 2017.
-
Yu, Licheng, Mohit Bansal, and Tamara Berg. “Hierarchically-Attentive RNN for Album Summarization and Storytelling.” *Proceedings of the 2017 ↩
-
Chandrasekaran, Arjun, Devi Parikh, and Mohit Bansal. “Punny Captions: Witty Wordplay in Image Descriptions.” arXiv preprint arXiv:1704.08224 (2017). ↩