In this article, I will try to round up some (mostly neural) approaches for semantic parsing and semantic role labeling (SRL). This is not an extensive review of these methods, but just a collection of my notes on reading some recent research on the subject. However, I do believe it covers most of the latest trends as well as their limitations.
But first, what is semantic parsing?
“Semantic” refers to meaning, and “parsing” means resolving a sentence into its component parts. As such, semantic parsing refers to the task of mapping natural language text to formal representations or abstractions of its meaning. A syntactic parser may generate constituency or dependency trees from a sentence, but a semantic parser may be built depending upon the task for which inference is required.
For example, we can build a parser that converts the natural language query “Who was the first person to walk on the moon?” to an equivalent (although complex!) SQL query such as “SELECT name FROM Person WHERE moon_walk = true ORDER BY moon_walk_date FETCH first 1 rows only.”
Semantic parsing is inherently more complicated than syntactic parsing because it requires understanding concepts from different word phrases. For instance, the following sentences should ideally map to the same formal representation.
Sentence 1: India defeated Australia.
Sentence 2: India secured the victory over the Australian team.
For this reason, semantic parsing is more about capturing the meaning of the sentence rather than plain rule-based pattern matching.
Semantic role labeling is a sub-task within the former, where the sentence is parsed into a predicate-argument format. The example given on the Wikipedia page for SRL explains this well. Given a sentence like “Mary sold the book to John,” the task would be to recognize the verb “to sell” as representing the predicate, “Mary” as representing the seller (agent), “the book” as representing the goods (theme), and “John” as representing the recipient. In this sense, SRL is sometimes also called shallow semantic parsing because the structure of the target representation is somewhat known.
In this article, I will describe models for both these tasks without explicit differentiation, mostly since the same models are found to work well on either task.
Learning sentence embeddings using deep neural models
Vector semantics have been used extensively in all NLP tasks, especially after word embeddings (Word2Vec, GloVe) were found to represent the synonymy-antonymy relations well in real space.
Similar to word embeddings, we can try to obtain dense vectors to represent a sentence, and then find some way to obtain the formal representation from it. Ivan Titov (University of Edinburgh) has recently proposed a couple of models which use LSTMs 1 and Graph CNNs 2 for dependency-based SRL task.
I will first explain the task. We work on datasets where the predicates are marked in the sentence, and the objective is to identify and label the arguments corresponding to each predicate. For instance, given the sentence “Mary eats an apple,” and the predicate marked as EATS, we need to label the words ‘Mary,’ ‘an,’ and ‘apple’ as agent, NULL, and theme, respectively. Also, since a single sentence may contain multiple predicates, the same word may get different labels for each predicate. Essentially, if we repeat the process once for each predicate, out task effectively reduces to a sequence labeling problem.
LSTM-based approach 1 : LSTMs (which are a type of RNNs that can preserve memory) have been used to model sequences since they were first introduced. In the first model, the sequence labeling is performed as follows.
- Vectors are obtained from each word by concatenating pre-trained embeddings (Word2Vec), random embeddings, and randomly initialized POS embeddings.
- The word vector also contains a 1-bit flag to mark whether it is the predicate in that particular training instance. This is done to ensure that the network treats each predicate differently.
- These are fed into a bi-LSTM layer to obtain the word’s context in the sentence.
- Finally, to label any word, we take the dot product of its hidden state with the predicate’s hidden state and obtain a softmax classifier over it as follows.
- Further, we can have the weight matrix parametrized on the role label $r$ as:
where the vectors in the dot product correspond to randomly initialized embeddings for the predicate lemma and the role, respectively.
GCN-based approach 2: In a second model, Graph Convolutional Networks (GCNs) have been used to represent the dependency tree for the sentence. In a very crude sense, a GCN input layer encodes the sentence into an $m X n$ matrix based on its dependency tree, such that each of the $n$ nodes of the tree is represented as an $m$-dimensional vector. Once such a matrix has been obtained, we can perform convolutions on it.
It is then evident that a one-layer GCN can capture information only about its immediate neighbor. By stacking GCN layers, one can incorporate higher degree neighborhoods.
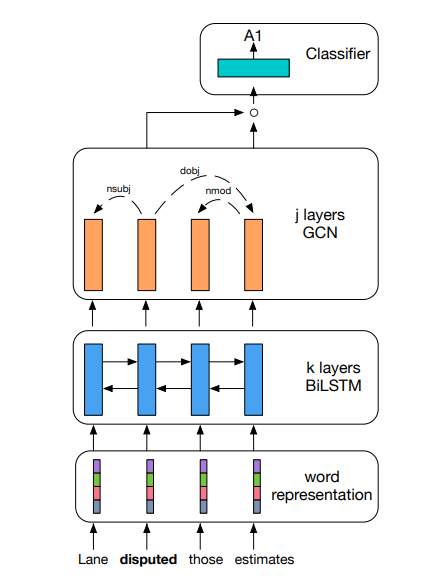
GCNs and LSTMs are complementary. Why? LSTMs capture long-term dependencies well but are not able to represent syntax effectively. On the other hand, GCNs are built directly on top of a syntactic-dependency tree so they capture syntax well, but due to the limitation of fixed-size convolutions, the range of dependency is limited. Therefore, using a GCN layer on top of the hidden states obtained from a bi-LSTM layer would theoretically capture the best of both worlds. This hypothesis has also been corroborated through experimental results.
Encoder-decoder model 3: In this paper, the task is broadened into formal representation rather than SRL. If we consider the formal representation as a different language, this is similar to a machine translation problem, since both the natural as well as formal representations mean the same. As such, it might be interesting to apply models used for MT to semantic parsing. This paper does exactly this.
An encoder converts the input sequence to a vector representation and a decoder obtains the target sequence from this vector.
- The encoder uses a bi-LSTM layer similar to the previous methods to obtain the vector representation of the input sequence.
- The final hidden state is fed into the decoder layer, which is again a bi-LSTM. The hidden states obtained from this layer is used to predict the corresponding output tokens using a softmax function.
- Alternatively, we can have a hierarchical decoder to account for the hierarchical structure of logical forms. For this purpose, we simply introduce a non-terminal token, say
, which indicates the start of a sub-tree. Other tokens may be used to represent the start/end of a terminal sequence or a non-terminal sequence. - To incorporate the tree structure, we concatenate the hidden state of the parent non-terminal with every child.
- Finally in the decoding step, to better utilize relevant information from the input sequence, we use an attention layer where the context vector is a weighted sum over the hidden vectors in the encoder.
While these models are very inspired and intuitive, they are all supervised. As such, they are constrained due to cost and availability of annotated data, especially since manually labeling semantic parsing output is a time-consuming process. In part 2 of this article, I will talk about some approaches which overcome this issue.
-
Marcheggiani, Diego, Anton Frolov, and Ivan Titov. “A simple and accurate syntax-agnostic neural model for dependency-based semantic role labeling.” arXiv preprint arXiv:1701.02593 (2017). ↩ ↩2
-
Marcheggiani, Diego, and Ivan Titov. “Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling.” arXiv preprint arXiv:1703.04826 (2017). ↩ ↩2
-
Dong, Li, and Mirella Lapata. “https://arxiv.org/pdf/1601.01280.pdf.” arXiv preprint arXiv:1601.01280 (2016). ↩